HUMAN-AI
ALGORITHM
知性と感性のAIを、
社会実装する。
SCROLL
WHAT’S
AI suite
AI suite とは?
AI suiteは、マルチモーダルAI技術を活用したAIプラットフォームサービスです。
長年培ってきた独自のAI技術をベースに、感情分析技術やLLMを活用したツール提供やプロダクト開発を行っています。

AI suiteの特長
マルチモーダルAIとは
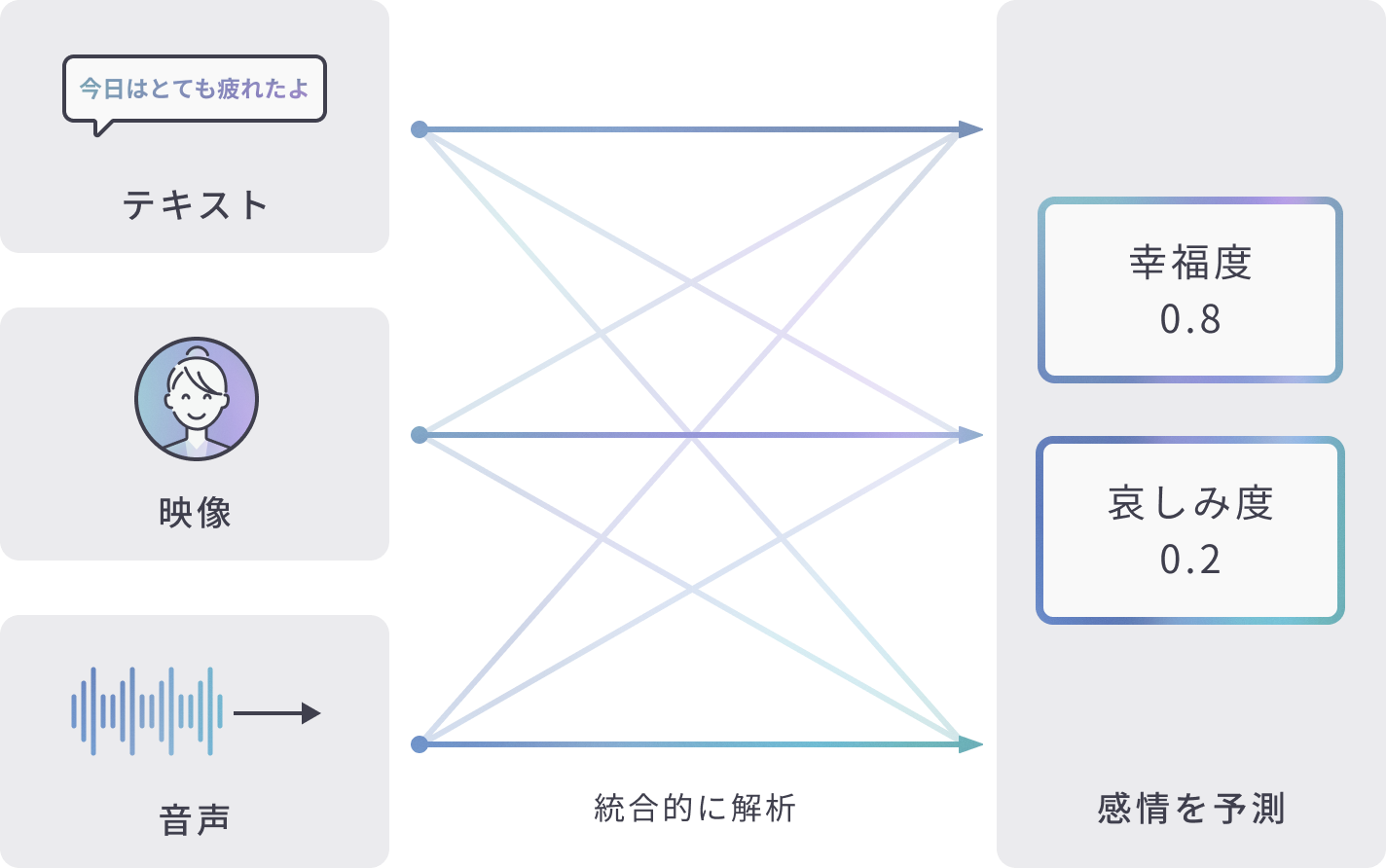
AI suiteのマルチモーダルAIは、テキスト(言語情報)、表情(映像情報)、声の抑揚(音声情報)の3つの入力情報を統合解析し、感情を予測することが可能です。
一つの情報だけではなく、複数の情報を統合的に解析する技術により、精度の高い感情予測を実現します。
01WHAT’S AI SUITE
USE CASES導入事例
02USE CASES

COLUMNコラム

これで完璧!生成AIおすすめ活用法4選&使いこなすコツ3つ
2024.4.112024.4.11

生成AIを用いるメリット|ビジネスで活用する際のデメリットも解説
2024.4.42024.4.4

生成AIにおけるリスクと対策|社会的な懸念や対処法についても解説
2024.3.292024.3.29
03COLUMN
NEWSお知らせ
2023.10.11
バーチャル空間でAIキャラクターとの自然な会話や紅茶を楽しむ「XR TEAROOM」を期間限定公開!
- トピックス
2023.10.6
第4回AI・人工知能EXPO【秋】に出展します
- トピックス
2023.7.3
Webサイトをリニューアルしました
- トピックス
2023.6.27
NHKニュースにメタバース総合展での弊社ブースが取り上げられました
- プレスリリース
2023.6.26
「【Afternoon Tea監修】人格保有型AI店員と自然な対話で紅茶を楽しむ「XRティールーム」を初公開」についてプレスリリースを発表しました
- プレスリリース
04NEWS