
コラムBERTとは何か:自然言語処理モデルにおけるChatGPTとの違いと特徴
BERTとは何か:自然言語処理モデルにおけるChatGPTとの違いと特徴
- 目次
BERTとは何か
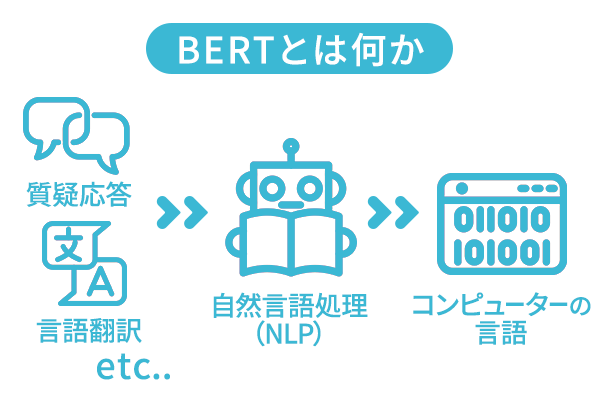
BERTとは何か? – 「Googleによって開発された自然言語処理モデル」
BERT(Bidirectional Encoder Representations from Transformers)は、Googleが開発した自然言語処理のための深層学習モデルです。BERTは、言語理解タスクを実行することができ、文の意味や文脈を理解することができます。
BERTの最も大きな特徴は、双方向性を持っていることです。つまり、文の前後を考慮した文脈理解ができます。これにより、高度な自然言語処理タスクを行うことが可能になります。
BERTは、文章の要約、文書分類、質問応答、言語翻訳など、様々な自然言語処理タスクに応用されています。BERTは、大規模なコーパス(文章の集まり)から事前に学習されたモデルであり、学習済みのモデルを転移学習することで、より小規模なデータセットでも高い精度で処理することができます。
BERTの目的 – 「どんな目的で開発/活用される技術なのか」
BERTの主な目的は、人間の言語理解能力に近い精度で自然言語を処理することです。これにより、テキストから意味を抽出することが可能になり、より高度な自然言語処理タスクを実現できます。
BERTは、文章の要約、文書分類、感情分析、機械翻訳、質問応答など、多様な自然言語処理タスクに応用されています。また、BERTは、様々な言語や分野にも適用可能であるため、グローバルな自然言語処理技術として注目を集めています。
BERTは、その高い精度と汎用性から、ビジネス分野や医療分野、政治分野など、様々な分野で利用されています。さらに、BERTは、オープンソースで公開されており、誰でも利用することができるため、自然言語処理技術の発展に大きく貢献しています。
BERT以外の言語モデル – 「他にどんな言語モデルがあるのか」
BERT以外にも、様々な言語モデルが存在します。例えば、GPT(Generative Pre-trained Transformer)は、OpenAIが開発した言語モデルで、文章生成や文章補完などのタスクに優れた精度を発揮します。
また、ELMo(Embeddings from Language Models)は、文脈を考慮した単語表現を生成することで、より高度な自然言語処理タスクを実現することができます。
さらに、ULMFiT(Universal Language Model Fine-tuning)は、プレーントークン(文の構成要素)を対象とした言語モデルであり、比較的小規模なデータセットでも高い精度を発揮します。
BERTと同様に、これらの言語モデルも、大量のデータセットを用いた事前学習によって高い性能を発揮します。ただし、それぞれの言語モデルは、特性や応用分野によって優れている点が異なります。そのため、自然言語処理タスクに応じて最適な言語モデルを選択することが重要です。
BERTの原理とその特徴
BERTは、双方向Transformerエンコーダーに基づいた深層学習モデルであり、大量のテキストデータを用いて事前学習されたモデルです。BERTは、双方向性を持っていることが最大の特徴であり、文脈を考慮して単語の意味を理解することができます。また、BERTは、テキスト内の単語の位置情報を学習することができるため、単語の順序を考慮した文脈理解が可能です。
BERTのモデル構造 – 「双方向Transformerエンコーダーに基づくモデル構造がどのように構成されているのか」
BERTは、マルチラベル分類タスクを実行するために訓練されたモデルであり、モデルは、双方向のエンコーダーによって構成されています。 エンコーダーは、単語の分散表現を生成し、文脈に基づいて単語の意味を理解するための入力データを受け取ります。
エンコーダーは、トランスフォーマーのブロックを複数積み重ねて構成されており、各ブロックは、自己注意機構とフィードフォワードニューラルネットワークからなっています。
BERTのトレーニング方法 – 「BERTが大量のテキストデータから事前学習する方法とその効果」
BERTは、大量のテキストデータを用いて事前学習されたモデルであり、2つの学習タスクを用いてトレーニングされます。
1つ目は、文のマスキングタスクであり、ランダムに選択された単語をマスクし、欠落した単語を予測することで文脈を理解します。2つ目は、次の文予測タスクであり、2つの文を与えられたときに、 2つ目の文が1つ目の文の後に来るかどうかを予測することで文脈理解を促進します。
これらの学習タスクにより、BERTは、自然言語処理タスクにおいて高い精度を発揮するようになりました。
BERTの特徴 – 「他の言語モデルと異なる点について」
BERTと他の言語モデルの主な違いは、双方向性と事前学習の方法です。他の言語モデルには、ELMoやULMFiTなどがありますが、ELMoは、単方向のLSTMを使用しており、ULMFiTは、言語モデルを階層的に訓練する方法を採用しています。
これに対して、BERTは、双方向のトランスフォーマーエンコーダーを使用し、大量のテキストデータを用いた事前学習により、高い精度を発揮することができます。また、BERTは、異なる自然言語処理タスクに対応するため、転移学習が容易であり、簡単にカスタマイズすることができます。BERTの高い性能は、様々な自然言語処理タスクに対して優れた精度を発揮するため、企業や研究機関から注目を集めています。
BERTの活用事例
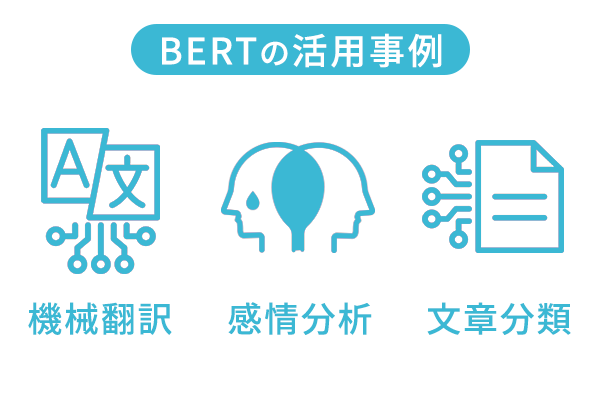
BERTは、自然言語処理の分野で広く活用されており、様々な事例があります。以下に、BERTが活用されている事例を3つ紹介します。
機械翻訳
一つ目は、機械翻訳技術の開発です。BERTは高い翻訳精度を実現しており、自然言語処理技術の中でも高い精度を持つため、機械翻訳にも応用することができます。BERTを用いることで、文脈に基づいた翻訳が可能になり、より自然な翻訳が実現できるようになっています。
感情分析
二つ目は、感情分析の分野です。BERTは、テキストから意味を理解することができるため、感情分析においても高い精度を発揮します。感情分析を用いることで、企業は、顧客のニーズや感情を把握することができ、より効果的なマーケティング戦略の立案に役立てることができます。
文章分類
三つ目は、文章分類です。教師データに存在しないラベルを予測する「Zero-shot Learning」という問題設定でテキスト分類が可能です。実際に、自然言語処理の分野ではトップの国際会議である、ACL2020でBERTを利用したモデルが提案されました。
最近では、ディープラーニングを用いた文章生成技術が進化する一方で、フェイクニュースを検知する研究も盛んに行われ、文章分類の技術が活用されています。
自然言語処理モデルの変遷・BERTの現在

自然言語処理の分野では、BERT以前にも多数の言語モデルが提唱されてきました。例えば、2013年にはword2vecが提唱され、2017年にはELMoが発表されました。そして、同じ年にBERTが発表され、自然言語処理の分野において大きな転換点となりました。
BERT以前の言語モデルについて
BERT以前には、word2vecやELMoなど多数の言語モデルが提唱されてきました。これらのモデルも自然言語処理において重要な役割を果たしてきましたが、BERTの登場によって自然言語処理の分野における大きな転換点が訪れました。
ChatGPTとBERTの関係性について
2022年12月初旬に登場したChatGPTは、自然言語処理分野における新たなターニングポイントとなりました。その開発には、GPT-3のような大規模言語モデル(LLM)の発展が加速したことが大きな要因でした。
一方、BERTはGoogleとトロント大学の研究者たちが提唱した言語モデルであり、自己注視機構により系列データを一括処理するTransformerアーキテクチャを採用しています。ChatGPTとBERTは、両方とも大規模なデータセットを用いた事前学習を行い、自然言語処理における高度なタスクに対応することができる点で共通しています。
自然言語処理モデルの戦国時代。我々はどう活用すべきか
OpenAIのChatGPTや、GoogleのBardなどの自然言語処理モデルが登場し、AI技術のブレイクスルーが続いています。これらのモデルは、自然言語に対する高度な理解力を持ち、非技術者でも扱えるレベルまで進化しています。
ビジネスシーンにおいても、これらの自然言語処理モデルを活用することで、顧客や市場の傾向を分析し、適切なマーケティング戦略を展開することができます。また、自動化されたチャットボットの導入によって、カスタマーサポートの効率化や、顧客とのコミュニケーション強化が期待できます。
さらに、BERTやChatGPTを利用した文書生成技術を活用することで、ビジネスレポートや契約書など、多くの時間と手間を要する業務の自動化が可能になります。
自然言語処理モデルの戦国時代には、多くの選択肢がありますが、ビジネスにおいては、最も効果的な活用方法を見つけることが重要です。今後も、AI技術の進化に合わせ、自然言語処理モデルをビジネスに活用する方法がさらに広がることが期待されます。